Модернизированные журналы кластера Windows Server 2016
По возможности, своевременное получение критически важных данных, поможет более быстро решить проблемы отказоустойчивости кластеровС диагностической точки зрения, первое улучшение в Windows Server 2016 связано с журналом диагностики кластера. Журнал диагностики кластера всегда был полезен для выявления ошибок, определения того, что привело к ошибке, что происходит во время ошибки и так далее. Но использование журнала кластера для определения таких вещей, как конфигурация кластера, процесс более сложный.
Содержание:
Журналы кластера
Получение нужных данных в нужное время, может иметь решающее значение для служб восстановления. При наличии всех имеющихся Service-Level Agreements (SLA) правильная диагностика имеет решающее значение для многих предприятий.
Например, вы хотите узнать ресурсы в кластере. Так журнал диагностики кластера показывает запуск службы кластеров, требуемая информация есть. Но для того, чтобы её найти потребуется долгий поиск в многих строках и объединение всех этих данных вместе, как продемонстрировано в следующем примере:
<Networks><vector len='4'>
<item><obj sig='NETW' id='1f509983-2478-4630-af8a-e13d2c486172' name='Cluster Network 2'/></item>
<item><obj sig='NETW' id='967df8d8-0f94-4d02-93d5-046fa1ce2369' name='Cluster Network 1'/></item>
<item><obj sig='NETW' id='99e6e621-0de5-4a1c-a468-a68057ee6278' name='Cluster Network 4'/></item>
<item><obj sig='NETW' id='a171b564-6b89-4c7d-91a5-f2dcbe450fbe' name='Cluster Network 3'/></item> </vector>
<LIVE id='.Live' name='.Live'>
<NODE id='2' name='2012R2N1'>
<ITFC id='62edcfaa-fb25-4108-ac2b-236b3520af3f' name='2012R2N1 - WAN'/> <ITFC id='884676e9-6df6-4a26-a423-c9b113a99056' name='2012R2N1 - iSCSI 2'/>
<ITFC id='65fa8c93-c242-45f0-88ab-9e26f0845c0b' name='2012R2N1 - Public'/>
<ITFC id='10962cca-3015-4380-8011-76e47ef575c4' name='2012R2N1 - iSCSI 1'/>
</NODE>
<NODE id='1' name='2012R2N2'>
<ITFC id='9e79c4c8-8d78-4d14-ab51-7a39d7191c4a' name='2012R2N2 - WAN'/>
<ITFC id='09569c99-262d-4f6b-95e4-f69185669f2b' name='2012R2N2 - iSCSI2'/>
<ITFC id='aa8f05e2-eeae-452c-9960-3905d0319fe1' name='2012R2N2 - Public'/>
<ITFC id='95d0074f-6ff6-4b5f-89a7-454fe2306332' name='2012R2N2 - iSCSI1'/>
</NODE>
</LIVE>
Получение этого небольшого количества информации влечёт за собой прохождение по 1000 или более строк в журналах. Задача, требующая массы времени. Поиск другой конкретной информации о конфигурации может прогнать вас через этот же набор записей, или даже больше.
Вы можете получить этот тип информации из других журналов или реестра, но это требует пересмотра информации из нескольких файлов. Если вы не на машине и кто-то собирает журналы для вас, этот человек может не включить все журналы. Так, что получение необходимой информации может оказаться более долгим, чем вы ожидаете.
Эта сложность была важным фактором для Windows Server 2016, поскольку она относится к отказоустойчивой кластеризации. По этой причине был изменён журнал диагностики кластера. При генерации журнала кластера в Windows Server 2016, собирается дополнительная информация, к которой вы можете получить быстрый доступ. Она разбита на различные разделы, как показано здесь:
[=== Cluster ===]
Эта секция даёт сведения о версии, времени выполнения, имени узла из которого пришёл журнал и т.д.
[=== Resources ===]
Список всех ресурсов (включая GUID) и параметров конфигурации этих ресурсов
[=== Groups ===]
Список всех групп (включая GUID) и параметров/конфигурации тех групп, владельцев узла, и т.д.
[=== Resource Types ===]
Список всех типов ресурсов (включая GUID) и параметров конфигурации, этих типов ресурсов
[=== Nodes ===]
Этот раздел даёт сведения об узлах, включая версии, время выполнения, идентификатор узла, и т.д.
[=== Networks ===]
Этот раздел предоставляет информацию о сетях, включая роль, схемы сети, метрики, поддержка RSS и т.д.
[=== Network Interfaces ===]
Этот раздел предоставляет информацию о сетях, включая имя, информацию о IP-адресе, и т.д.
[=== System ===]
Все записи журнала событий системы с отказоустойчивым кластером как источник
[=== Microsoft-Windows-FailoverClustering/Operational logs ===]
Все события с канала Microsoft-Windows-FailoverClustering/Operational, который даёт информацию о формах кластера, узле соединения и т.д.
[=== Microsoft-Windows-ClusterAwareUpdating-Management/Admin logs ===]
Все события из Microsoft-Windows-ClusterAwareUpdating-Management/Admin канала, который даёт информацию о Cluster Aware Updatin
[=== Microsoft-Windows-ClusterAwareUpdating/Admin logs ===]
Все события от Microsoft-Windows-ClusterAwareUpdating/Admin канала, который даёт информацию о Cluster Aware Updating
[=== Microsoft-Windows-FailoverClustering/DiagnosticVerbose ===]
Это на самом деле новый канал событий, который даёт вывод для журнала кластера аналогичный Debug Level 5, без необходимости его установки. Вы можете использовать эту информацию для глубокого изучения происходящих в кластере заходов и выходов, которая выдаётся в более подробном выводе.
[=== Cluster Logs ===]
Это вывод, который вы обычно видите в журнале кластера.
Очевидно, что в этом журнале много чего есть. Использование только этого одного журнала может уменьшить время, которое вы тратите на поиск информации или попытку решить проблему. Вместо того чтобы изучать три или более файлов, которые могут быть загружены в своих собственных форматах, в трёх различных приложениях, вам теперь нужно просмотреть только один файл.
Другая полезная вещь этого журнала, если вы генерируете его без коммутаторов, отображается все каналы событий (например, событие системы). Так вы реально можете получить любую, относящуюся к конкретной проблеме, историю. Для случаев, в которых вам нужно воспроизвести ошибку состояния и вам не обязательна вся история, можно создать журнал за последние пять минут (TimeSpan = 5).
По умолчанию, новый журнал кластера использует этот же промежуток времени, пять минут, для всех каналов событий, поэтому вам не придётся иметь дело с излишне большим файлом.
Дамп активной памяти
Ещё одна, относящаяся к диагностике, новая функция - способность захватывать дампы памяти. Представьте, что у вас большой кластер Hyper-V, и каждый из узлов имеет 512 ГБ оперативной памяти. Если узел имеет проблему, и вы создаёте дамп памяти, в котором содержится память пользователя и ядра, этот дамп памяти будет больше 512 ГБ. Попытка работать с файлом такого размера будет кошмаром.
Во-первых, вы должны убедиться, что у вас на диске достаточно свободного места для хранения файла этого размера. Затем, прежде чем вы сможете его открыть, вам придётся потратить много времени на то, чтобы его сжать, загрузить и разархивировать. Если проблема связана с хост-сервером, и вы используете, имеющие 500 ГБ памяти, виртуальные машины, эта информация вам не нужна, потому что не относится к узлу.
Для этого есть новый параметр дампа - Active Memory Dump. Этот параметр отражает только используемую узлом на самом деле память. Если узел активно использует только 5 ГБ памяти, будет создан дамп памяти 5 GB. Этот меньший дамп гораздо проще изучить чем 512 Гб файл в предыдущем сценарии.
Параметры Active Memory Dump находятся в том же месте, что и настройки обычного дампа, в диалоговом окне Startup And Recovery свойств системы.
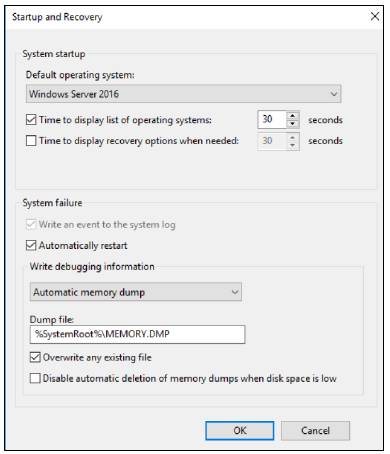
Настройки Active Memory Dump
Примечание. Дампы памяти отказоустойчивой кластеризации, для захвата дампов при достижении тайм-аутов, были интегрированы с Live Dump. Затем, для определения причины проблемы, можно проанализировать эти дампы. А также, для сохранения и включения других журналов, они интегрируются с Windows Error Reporting.
В зависимости от ресурса ожидания и настройки отказоустойчивого кластера, Live Dump может заставить машину выдать stop-ошибку (т.е., синий экран) и, для создания дампа памяти, привести к сбою машины. Несмотря на то, что дамп памяти полезен при определении причины проблемы, для создания дампа, машина перезагружается, что приводит к простою. Однако с интеграцией Live Dump, дамп памяти создаётся во время работы машины, в фоновом режиме, что не влияет на производство.
Основа этой функции -- сбор достаточного количества журналов / дампов для службы поддержки Microsoft. Чтобы она могла более эффективно устранять, возникшие у клиентов при использовании кластеров, неполадки. Цель в том, чтобы собрать достаточную информацию, с помощью которой служба поддержки могла решить проблему по звонку клиента, вместо того, чтобы просить его воспроизвести проблему, а затем ждать, когда он это сделает.
Диагностика имени сети
Windows Server 2016 содержит улучшения, связанные с диагностикой проблем с именами сетей. Время от времени некоторые из событий беспорядочны или даже отсутствуют. Например, ранее проблемы с обновлением DNS приводили к общей ошибке, указывающей, что DNS не может быть обновлён. Но уведомление об ошибке не указывало, почему DNS не может быть обновлён.
Это может иметь несколько причин:
- DNS не принимает динамические обновления.
- Вы используете безопасный DNS-сервер, и кластер не имеет соответствующих прав.
- На DNS-сервер поступают таймауты.
Устранение таких событий требовало времени, потому что, прежде чем вы могли сосредоточиться на определённой области и сузить проблему, вы должны были рассмотреть их в общих чертах. В Windows Server 2016 события обновляются, включая конкретную ошибку.
Итак, если ошибка вызвана одной из упомянутых в списке причин, вы получаете уведомление об ошибке и можете сразу сосредоточиться на её причине. Это обеспечивает более быстрое решение, потому что вам не нужно устранять проблему, которая не существует.
Кроме того, для того, чтобы предотвратить проблему, которая возможно и не произойдёт в течение нескольких дней или недель, добавлены дополнительные проверки для имени сети.
В каждом онлайн / автономном режиме ресурса и каждый час, когда это имя находится в сети, Windows Server 2016 проверяет следующее:
- Доступный для поиска контроллер домена,
- Синхронизированный пароль Cluster Name Object (CNO)
- Включённый в Active Directory CNO
- Существующий объект CNO и виртуальный компьютер (VCO) в Active Directory
Windows Server 2016 также включает несколько дополнительных тестов в проверке кластеров для сетевых имён, чтобы сделать следующее:
- Проверить, что CNO и VCO имеет больше 15 символов
- Убедится, что CNO имеет права на создание разрешений для компьютера в организационном подразделении (OU) в Active Directory, членом которого он является
- Убедится, что можно войти в CNO и соответствующий VCO
- Убедится, что группа локальных пользователей узла имеет членство CLISUR и NT AUTHORITY \ Authenticated Users
Предыдущие элементы обычно являются причиной проблем с именами сетей, поэтому были добавлены эти новые диагностические средства.